
 AI-Taxi App
AI-Taxi App AI-Food App
AI-Food App AI-Property Mgmt App
AI-Property Mgmt App AI-CRM
AI-CRM AI-Fantasy App
AI-Fantasy App
 Web Development
Web Development App Development
App Development Business & Startup
Business & Startup Hire Developer
Hire Developer
 Digital Marketing
Digital Marketing Lead-generation
Lead-generation Creative Agency
Creative Agency Branding Agency
Branding Agency Augmented Reality
Augmented Reality Virtual Reality
Virtual Reality Internet of Things
Internet of Things Artificial Intelligence
Artificial Intelligence Blockchain
Blockchain Chatbot
Chatbot
AI has been the focus of my life's work, as for many of my research colleagues. Ever since programming AI for computer games as a teenager, and throughout my years as a neuroscience researcher trying to understand the workings of the brain, I’ve always believed that if we could build smarter machines, we could harness them to benefit humanity in incredible ways.
This promise of a world responsibly empowered by AI continues to drive our work at Google DeepMind. For a long time, we’ve wanted to build a new generation of AI models, inspired by the way people understand and interact with the world. AI that feels less like a smart piece of software and more like something useful and intuitive — an expert helper or assistant.
Today, we’re a step closer to this vision as we introduce Gemini, the most capable and general model we’ve ever built.
Gemini is the result of large-scale collaborative efforts by teams across Google, including our colleagues at Google Research. It was built from the ground up to be multimodal, which means it can generalize and seamlessly understand, operate across and combine different types of information including text, code, audio, image and video.
Gemini is also our most flexible model yet — able to efficiently run on everything from data centers to mobile devices. Its state-of-the-art capabilities will significantly enhance the way developers and enterprise customers build and scale with AI.
We’ve optimized Gemini 1.0, our first version, for three different sizes:
- Gemini Ultra — our largest and most capable model for highly complex tasks.
- Gemini Pro — our best model for scaling across a wide range of tasks.
- Gemini Nano — our most efficient model for on-device tasks.
State-of-the-art performance
We've been rigorously testing our Gemini models and evaluating their performance on a wide variety of tasks. From natural image, audio and video understanding to mathematical reasoning, Gemini Ultra’s performance exceeds current state-of-the-art results on 30 of the 32 widely-used academic benchmarks used in large language model (LLM) research and development.
With a score of 90.0%, Gemini Ultra is the first model to outperform human experts on MMLU (massive multitask language understanding), which uses a combination of 57 subjects such as math, physics, history, law, medicine and ethics for testing both world knowledge and problem-solving abilities.
Our new benchmark approach to MMLU enables Gemini to use its reasoning capabilities to think more carefully before answering difficult questions, leading to significant improvements over just using its first impression.
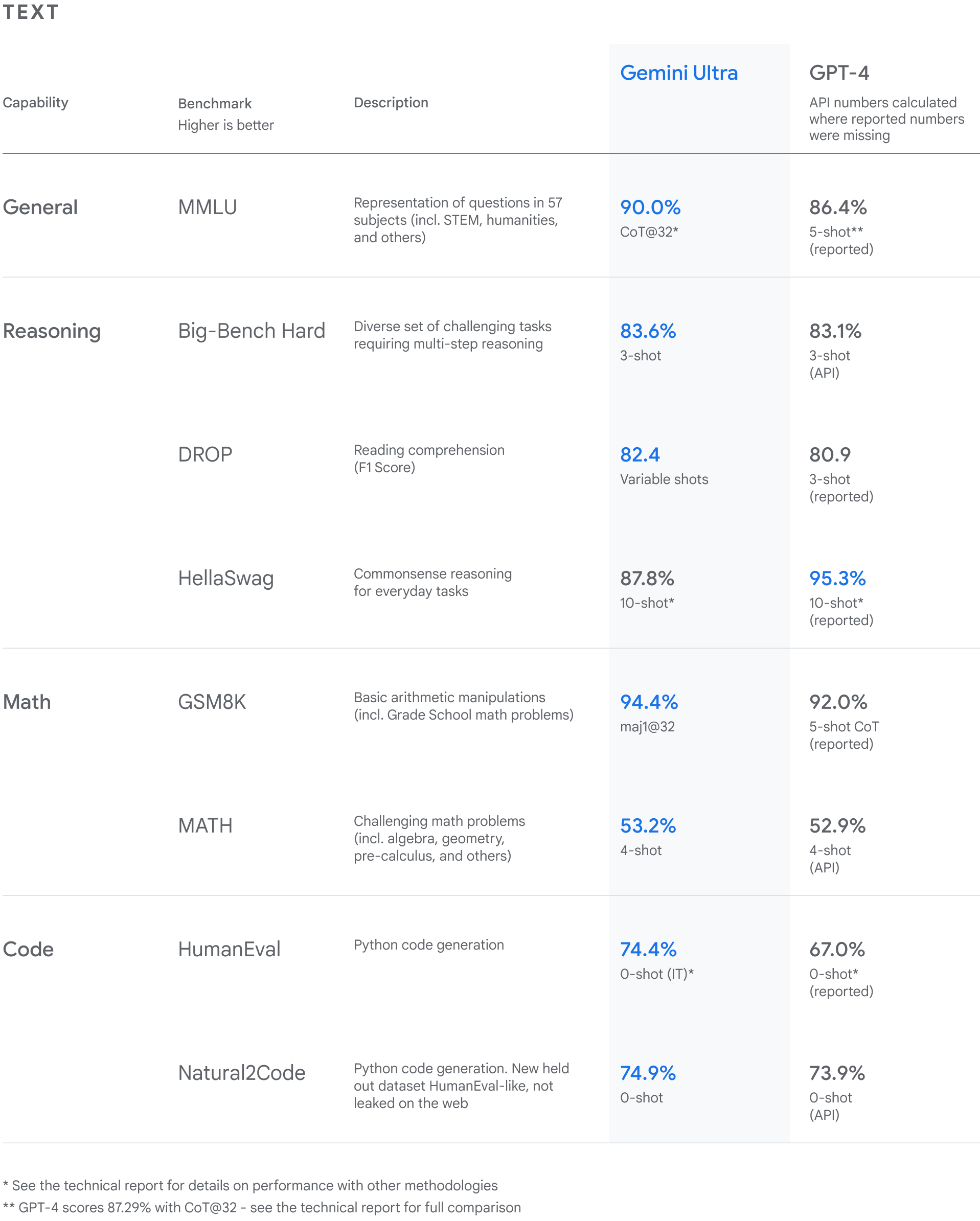
Gemini surpasses state-of-the-art performance on a range of benchmarks including text and coding.
Gemini Ultra also achieves a state-of-the-art score of 59.4% on the new MMMU benchmark, which consists of multimodal tasks spanning different domains requiring deliberate reasoning.
With the image benchmarks we tested, Gemini Ultra outperformed previous state-of-the-art models, without assistance from optical character recognition (OCR) systems that extract text from images for further processing. These benchmarks highlight Gemini’s native multimodality and indicate early signs of Gemini's more complex reasoning abilities.
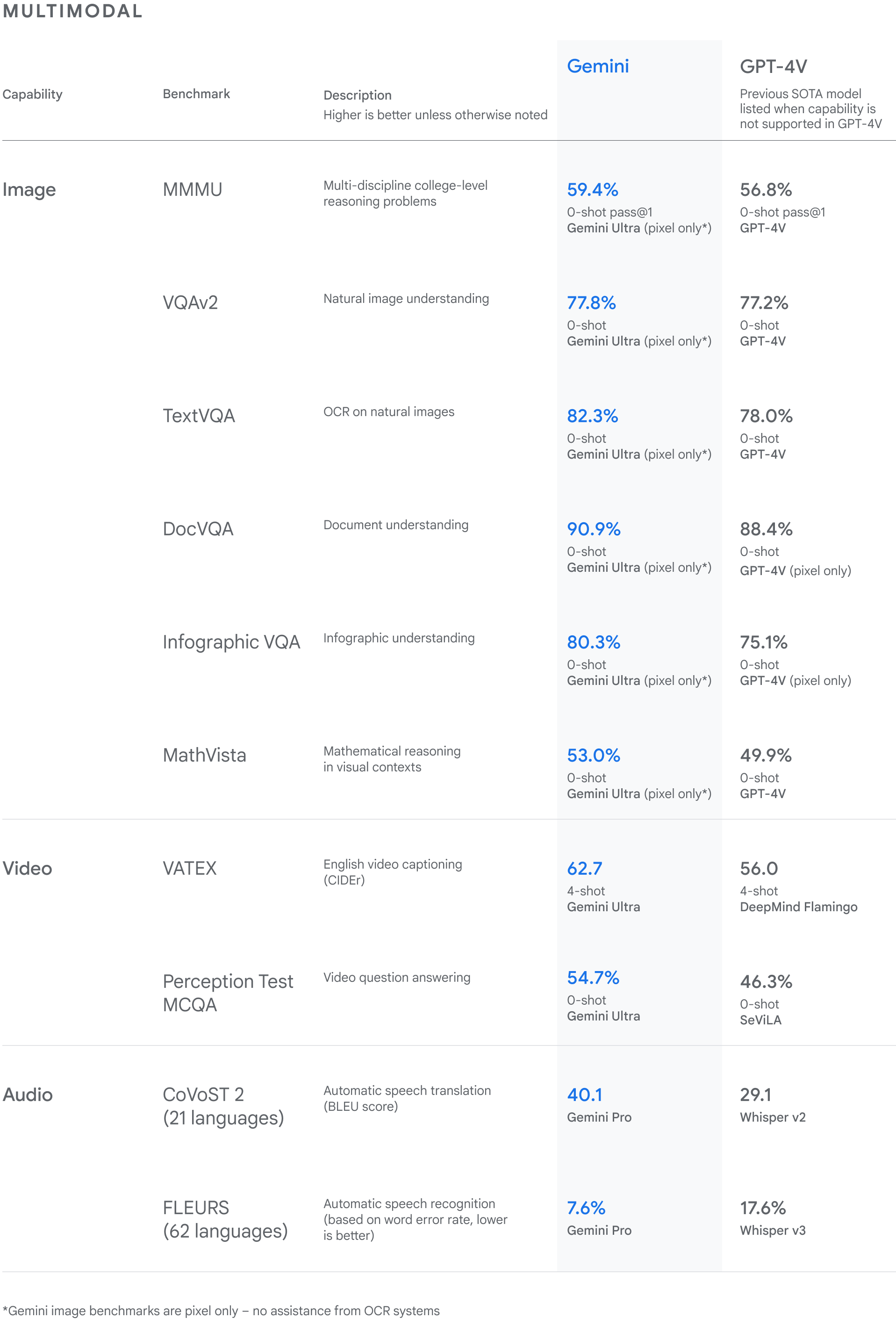
Next-generation capabilities
Until now, the standard approach to creating multimodal models involved training separate components for different modalities and then stitching them together to roughly mimic some of this functionality. These models can sometimes be good at performing certain tasks, like describing images, but struggle with more conceptual and complex reasoning.
We designed Gemini to be natively multimodal, pre-trained from the start on different modalities. Then we fine-tuned it with additional multimodal data to further refine its effectiveness. This helps Gemini seamlessly understand and reason about all kinds of inputs from the ground up, far better than existing multimodal models — and its capabilities are state of the art in nearly every domain.
Sophisticated reasoning
Gemini 1.0’s sophisticated multimodal reasoning capabilities can help make sense of complex written and visual information. This makes it uniquely skilled at uncovering knowledge that can be difficult to discern amid vast amounts of data.
Its remarkable ability to extract insights from hundreds of thousands of documents through reading, filtering and understanding information will help deliver new breakthroughs at digital speeds in many fields from science to finance.
Understanding text, images, audio and more
Gemini 1.0 was trained to recognize and understand text, images, audio and more at the same time, so it better understands nuanced information and can answer questions relating to complicated topics. This makes it especially good at explaining reasoning in complex subjects like math and physics.
Advanced coding
Our first version of Gemini can understand, explain and generate high-quality code in the world’s most popular programming languages, like Python, Java, C++, and Go. Its ability to work across languages and reason about complex information makes it one of the leading foundation models for coding in the world.
Gemini Ultra excels in several coding benchmarks, including HumanEval, an important industry-standard for evaluating performance on coding tasks, and Natural2Code, our internal held-out dataset, which uses author-generated sources instead of web-based information.
Gemini can also be used as the engine for more advanced coding systems. Two years ago we presented AlphaCode, the first AI code generation system to reach a competitive level of performance in programming competitions.
Using a specialized version of Gemini, we created a more advanced code generation system, AlphaCode 2, which excels at solving competitive programming problems that go beyond coding to involve complex math and theoretical computer science.
When evaluated on the same platform as the original AlphaCode, AlphaCode 2 shows massive improvements, solving nearly twice as many problems, and we estimate that it performs better than 85% of competition participants — up from nearly 50% for AlphaCode. When programmers collaborate with AlphaCode 2 by defining certain properties for the code samples to follow, it performs even better.
We’re excited for programmers to increasingly use highly capable AI models as collaborative tools that can help them reason about the problems, propose code designs and assist with implementation — so they can release apps and design better services, faster.
Gemini Pro in Google products
Starting today, Bard will use a fine-tuned version of Gemini Pro for more advanced reasoning, planning, understanding and more. This is the biggest upgrade to Bard since it launched. It will be available in English in more than 170 countries and territories, and we plan to expand to different modalities and support new languages and locations in the near future.
We’re also bringing Gemini to Pixel. Pixel 8 Pro is the first smartphone engineered to run Gemini Nano, which is powering new features like Summarize in the Recorder app and rolling out in Smart Reply in Gboard, starting with WhatsApp, Line and KakaoTalk1 — with more messaging apps coming next year.
In the coming months, Gemini will be available in more of our products and services like Search, Ads, Chrome and Duet AI.
We’re already starting to experiment with Gemini in Search, where it's making our Search Generative Experience (SGE) faster for users, with a 40% reduction in latency in English in the U.S., alongside improvements in quality.
Building with Gemini
Starting on December 13, developers and enterprise customers can access Gemini Pro via the Gemini API in Google AI Studio or Google Cloud Vertex AI.
Google AI Studio is a free, web-based developer tool to prototype and launch apps quickly with an API key. When it's time for a fully-managed AI platform, Vertex AI allows customization of Gemini with full data control and benefits from additional Google Cloud features for enterprise security, safety, privacy and data governance and compliance.
Android developers will also be able to build with Gemini Nano, our most efficient model for on-device tasks, via AICore, a new system capability available in Android 14, starting on Pixel 8 Pro devices. Sign up for an early preview of AICore.
For more information contact : support@mindnotix.com
Mindnotix Software Development Company



